
Video
Abstract
Video object removal has achieved advanced performance due to the recent success of video generative models. However, when addressing the side effects of objects, e.g., their shadows and reflections, existing works struggle to eliminate these effects for the scarcity of paired video data as supervision. This paper presents ROSE, termed Remove Objects with Side Effects, a framework that systematically studies the object’s effects on environment, which can be categorized into five common cases: shadows, reflections, light, translucency and mirror. Given the challenges of curating paired videos exhibiting the aforementioned effects, we leverage a 3D rendering engine for synthetic data generation. We carefully construct a fully-automatic pipeline for data preparation, which simulates a large-scale paired dataset with diverse scenes, objects, shooting angles, and camera trajectories. ROSE is implemented as an video inpainting model built on diffusion transformer. To localize all object-correlated areas, the entire video is fed into the model for reference-based erasing. Moreover, additional supervision is introduced to explicitly predict the areas affected by side effects, which can be revealed through the differential mask between the paired videos. To fully investigate the model performance on various side effect removal, we presents a new benchmark, dubbed ROSE-Bench, incorporating both common scenarios and the five special side effects for comprehensive evaluation. Experimental results demonstrate that ROSE achieves superior performance compared to existing video object erasing models and generalizes well to real-world video scenarios.
Data Preparation Pipeline
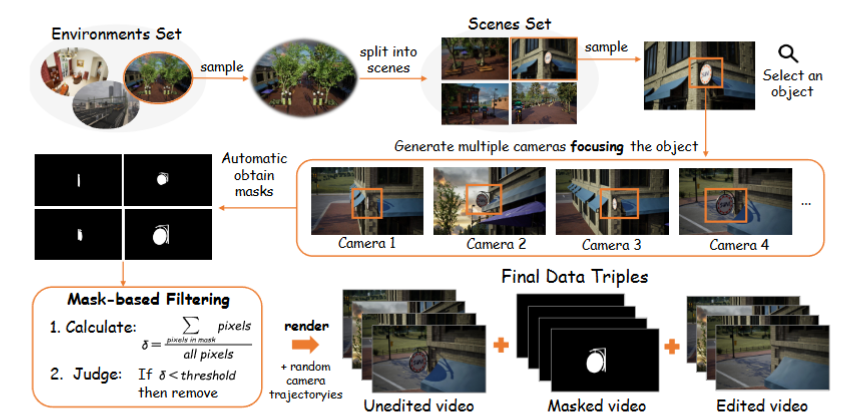
Method
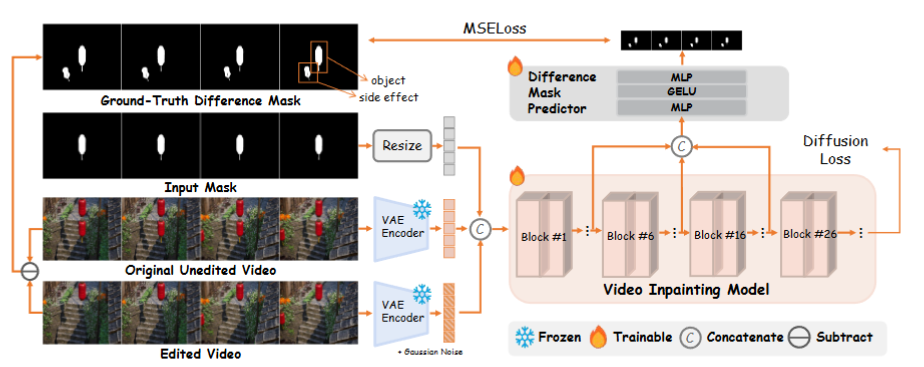
In brief, ROSE is implemented as an inpainting model continued from the foundation video generative models (the Wan2.1 model in this paper). Following the general architecture in diffusion-based inpainting models, we extend the model input with the original input video together with object masks. Distinguished from the typical setting that multiply the mask onto input video, we directly feed the whole video to assist the understanding on environment. The input masks, with precise boundary generated by 3D engine, are further augmented to enhance model robustness. To better supervise the model to localize the subtle object-environment interactions, we introduce an additional difference mask predictor to explicitly predict the side effect areas.
BibTeX
@article{miao2025rose,
title={ROSE: Remove Objects with Side Effects in Videos},
author={Miao, Chenxuan and Feng, Yutong and Zeng, Jianshu and Gao, Zixiang and Liu, Hantang and Yan, Yunfeng and Qi, Donglian and Chen, Xi and Wang, Bin and Zhao, Hengshuang},
journal={arXiv preprint arXiv:2508.18633},
year={2025}
}